Github: https://github.com/argoproj
一、简介#
Argo Workflow 是一个开源的、基于 Kubernetes 的工作流引擎,用于编排和运行容器化应用的工作流程。它使用 YAML 文件来定义工作流、依赖关系和参数。
Argo Workflow 还支持任务的重试、跳过、并行执行和失败处理等功能。它提供了丰富的工作流控制和监控功能,可以查看工作流的状态、日志和执行历史,并支持自定义的事件触发和通知机制。
目前Argo团队下中有如下几个子项目:
- argoproj
Common project repo for all Argo Projects - gitops-engine
Public Democratizing GitOps - argo-workflows
Workflow engine for Kubernetes - argo-cd
Declarative continuous deployment for Kubernetes. - argo-events
Event-driven automation framework - argo-rollouts
Progressive Delivery for Kubernetes
cd和rollouts一个是持续交付工具,一个是渐进式发布工具。
workflows和events一个是基于容器的任务编排工具,一个是事件驱动框架。这两者搭配可以设计出一个由新建任务事件触发从而启动工作流的方案。
流程如下:
![[content/docs/programmer/base/argo_events_workfows.png]]
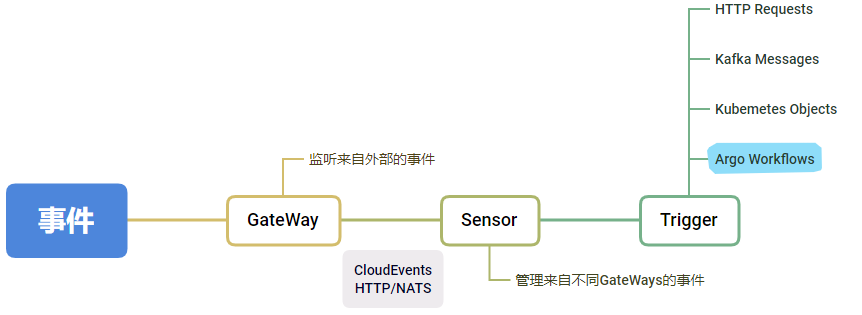
sensor作用#
- 使事件转发和处理松耦合
- Trigger事件的参数化,比如根据事件内容动态生成
二、Argo Workflow编排示例#
以下是一个扔硬币和打印结果的示例,借此可以熟悉一下
Workflow的编排语法
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: coinflip-recursive-
spec:
entrypoint: coinflip
templates:
- name: coinflip
steps:
- - name: flip-coin
template: flip-coin
- - name: heads
template: heads
when: "{{steps.flip-coin.outputs.result}} == heads"
- name: tails
template: coinflip
when: "{{steps.flip-coin.outputs.result}} == tails"
- name: flip-coin
script:
image: python:alpine3.6
command: [python]
source: |
import random
result = "heads" if random.randint(0,1) == 0 else "tails"
print(result)
- name: heads
container:
image: alpine:3.6
command: [sh, -c]
args: ["echo \"it was heads\""]至于部署Argo的步骤网上都有,为了精简文章就不在此赘述。下面关于一些在使用中需要注意的重要问题进行一些说明。
三、空间和性能#
ETCD占用#
因为Argo是基于Kubernetes的,所以空间问题一般不需要怎么关注,但如果在使用场景中需要频繁创建工作流,还是需要关注一下etcd的空间情况。因为Kubernetes集群中的配置、运行状态和其他各项关键信息都存储在etcd,在频繁创建工作流、且工作流很长时,这类信息会占据大量空间:
ETCDCTL_API=3 etcdctl --cacert /etc/kubernetes/pki/etcd/ca.crt --cert /etc/kubernetes/pki/etcd/healthcheck-client.crt --key /etc/kubernetes/pki/etcd/healthcheck-client.key --write-out=table endpoint status| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
|---|---|---|---|---|---|---|---|---|---|
| 127.0.0.1:2379 | 871f72e4ab5a28e8 | 3.5.0 | 104 MB | true | false | 35 | 348058564 | 348058564 |
根据提供的信息,可以看到以下解释:
- VERSION: etcd的版本为3.5.0。
- DB SIZE: etcd数据库当前占用的空间大小为104 MB。
- RAFT APPLIED INDEX: 当前etcd集群已应用的Raft Index为348058564。
- ERRORS: 没有显示任何错误信息。 总体上,这些信息展示了etcd集群的状态,包括节点角色、版本、数据库大小等,经过测试,创建100个十步左右的工作流需要占用20mb空间。
性能#
以下测试全部是通过创建一个概率性失败和重试的workflow测试而来:
- 它总共包括三步(第二步和第三步并行执行)
- 每一步都有一定的几率失败,失败后每一步最多重试10次,一旦成功后进入下一步
- 可以通过调节失败几率模拟出在实际环境中各个workflow分别处于不同进度的情况
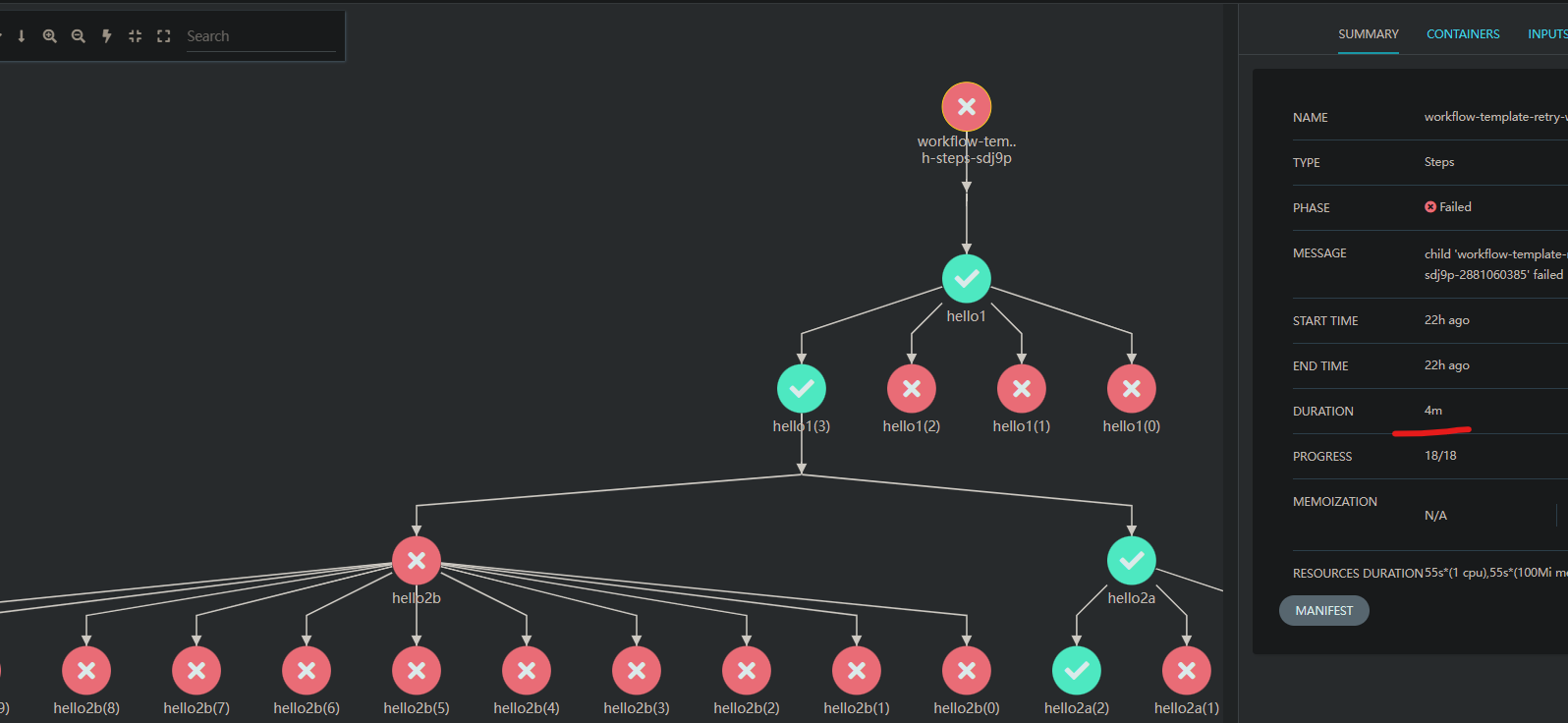
下图中第一步一共重试了四次,失败三次,第四次时成功,随后2b全部失败,2a第三步成功,整个工作流耗时4分钟
![[三步随机出错workflow.png]]
 在并发启动十五个工作流时,并且每一步都保证100%成功,整个流程花费2min左右,三个子步骤分别花费50-60秒。
![[全部成功的树状图.png]]
![[全成功workflow耗时.png]]
![[全成功的step耗时.png]]
在并发启动十五个工作流时,并且每一步都保证100%成功,整个流程花费2min左右,三个子步骤分别花费50-60秒。
![[全部成功的树状图.png]]
![[全成功workflow耗时.png]]
![[全成功的step耗时.png]]
在全部错误时,并且每一步都保证100%失败,总计经历11次尝试,整个流程花费10分钟左右,11个子步骤分别花费60秒左右 ![[全部失败的树状图.png]] ![[全错误workflow耗时.png]] ![[全错误的step耗时.png]]
可见每一步成功与否,与执行花费无关。不会出现错误重试避让成功工作流的现象。
使用argo submit retry_template.yaml -n websafe --watch 和 kubectl get pod -n {NAMESPACE} | grep workflow查看工作流运行状态,可知在工作流的每一步执行时都是实时初始化pod,所以以上花费约等于每一步初始化pod所用的时间。即以上时间是在运行逻辑之外无法优化的固定时间花费。
![[watch_workflow.png]]
![[work_flow_pod.png]]
总结#
由以上信息可见Argo WorkFlow有基于 Kubernetes的简单、易用、便于迁移的优点,但同时有启动速度慢,执行工作流的每一步时都具有额外消耗的缺点。
所以它适用于不关注实时性的业务,本身执行时间长的任务。例如AI中的模型训练,可以令每次训练都无需关注环境配置,可以做到自动资源、埋点分析和生成报表。例如在以下场景中: ![[ai_model_workflow.png]] 训练人员可以通过yaml文件自由更换训练、测试数据,选择输出模型发布方案。可以很方便的查看每一阶段信息,且不用编写代码关注运行环境。 进了工作流程中步骤之间的松耦合,并开辟了在未来工作流中重用组件的可能性。